
常微分方程一
学习视频 https://www.bilibili.com/video/BV1bx411s7pb?from=search&seid=18075226513527190717
方程:恒等式里面包含了未知
微分方程:未知量里既有自变量、未知函数,又有未知函数的导数的函数方程

讲解的场景都是物理的场景,前两个视频里面主要是一些基础的概念性的知识
无监督学习之wordEmbedding
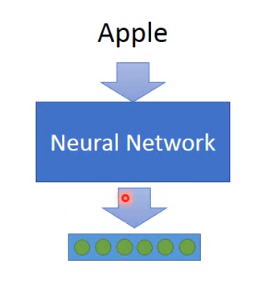
强化学习8.7-8.11
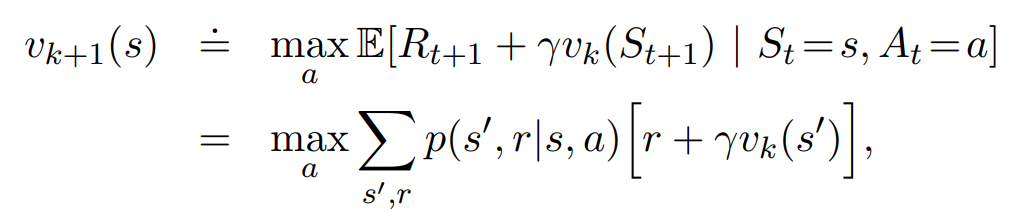
Chapter 3 Fairness in cooperative Mutiagent Systems
PER
paper:
https://arxiv.org/abs/1511.05952
Motivation
Experience transitions were uniformly, sampled from a replay memory. However, this approach simply replays transitions at the same frequency that they were originally experienced, regardless of their significance.
强化学习经典论文
强化学习读书(1.1-6.3)
Ch1.1-Ch1.6:崔昊川
https://blog.csdn.net/qq_41608822/article/details/105902504
Ch2.1-Ch2.4:韦国梁
见正文
Ch2.5-Ch2.8:崔昊川
https://blog.csdn.net/qq_41608822/article/details/105928928
Ch3.1-Ch3.3:韦国梁
见正文
FairnessIsNotStatic
Fairness Is Not Static
Motivation:
当前的Fairness都是静态的,数据都是fixed,而长期动态的环境中,现有的公平算法可能并不适用。
主要内容:
主要介绍了三个 ml-fairness-gym 的仿真环境,通过实验与静态的方法对比,发现静态方法在动态环境中可能会有一些问题。