
监督学习本质的工作是要最小化loss
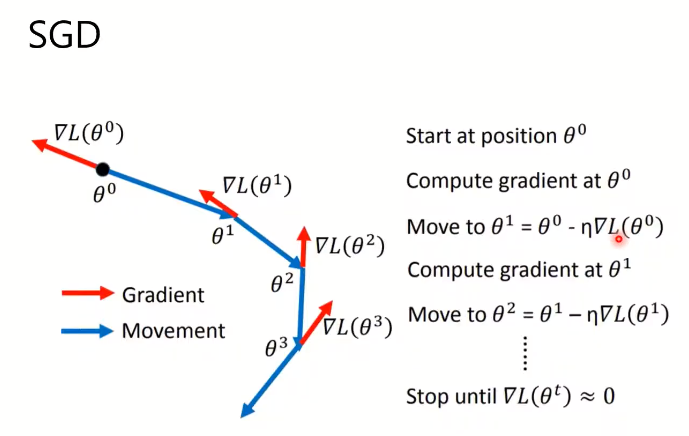
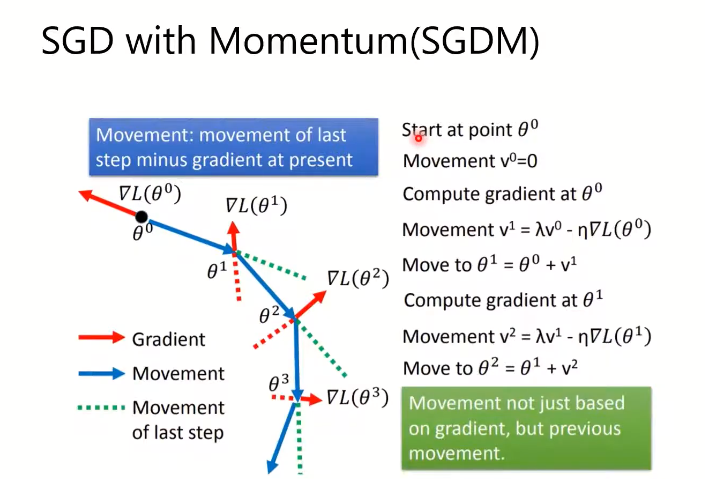
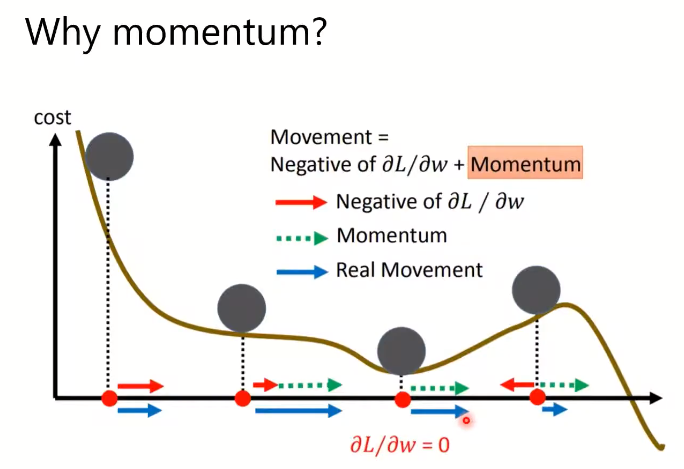
SGDM相当于每次的梯度更新累计了过去的梯度,优势在于可以收敛到一些更小的极小值
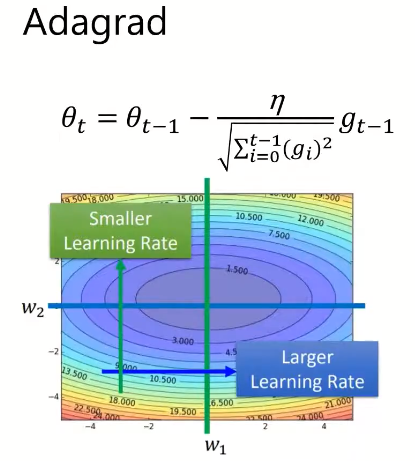
将learning rate除一个梯度的求和,调整learning rate,在梯度很大的时候减少learning rate
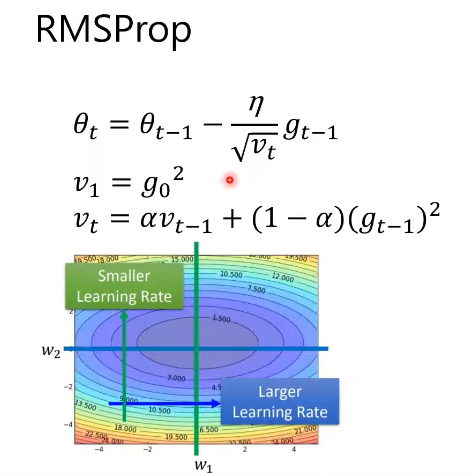
相当于对adagrad的一个改进,个人理解就是这样不会造成learning rate 越来越小学不下去

RMSProp仍然会停在local optima,使用的还是直接的梯度,只是调整了合适的learning rate
Adam结合了SGDM和RMSProp
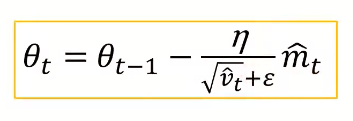
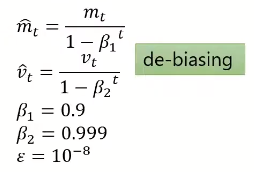
m和v与之前的方式有细微的区别,都除了一个和t相关的数来让值比较准确(具体作用还没懂)