目标
word embedding要做的是将每一个word project到高维空间中
Training data是text 没有对应的lable
通过上下文的关联来判断是否是相同的class
Counted based

两个词出现的次数越接近,两个词对应的vector就越接近
所以使用的内积的方式去逼近N_i,j
Prediction based
用前一个词去预测后一个词
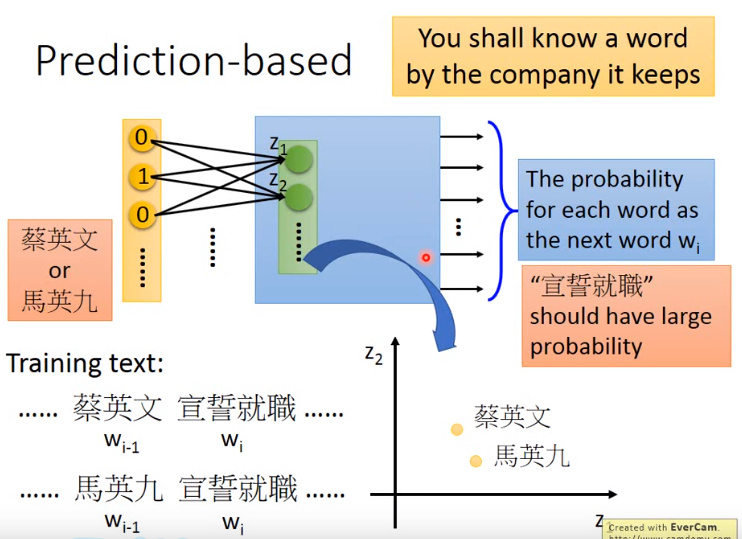
输入是word的one hot的值,对应到hidden layer z1 z2 … zn 表示对应维度的值(我的理解是这一层是隐藏层的最后一层),网络的输出是wi的概率
这样训练存在困难,因为给上一个词得到下一个词的概率这件事很困难。所以考虑几个词一起输入,比如$w{i-1}$和$w{i-2}$一起输入
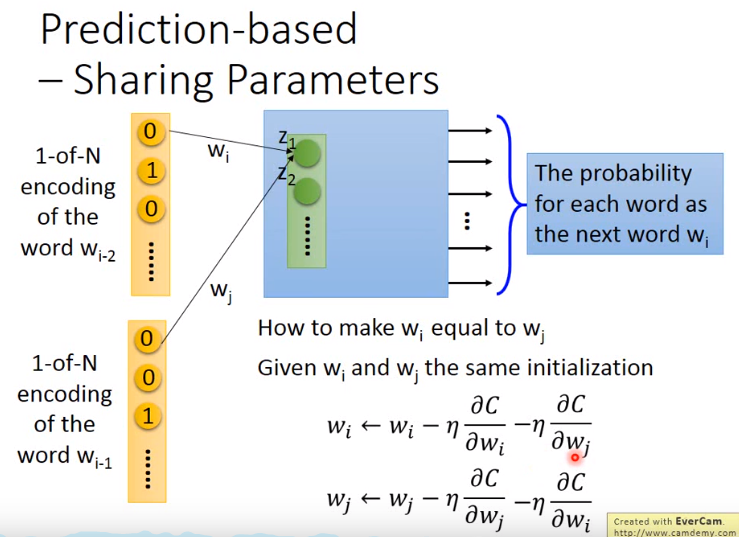
一个通常的处理方式是,input的参数使用相同的参数。方式:使用如图同样的初始化参数,然后更新使用的是所有词对应的参数。
CBOW
使用前面的词和后面的词去做预测
skip-gram
使用中间的词去预测两端的
其中,CBOW和skip_gram的神经网络使用的其实是一层的线性层

word embedding可以学习到词之间的一些关联
(个人想法,是不是可以采用这种方式去做词语之间的因果关系,或者是其他的关系)
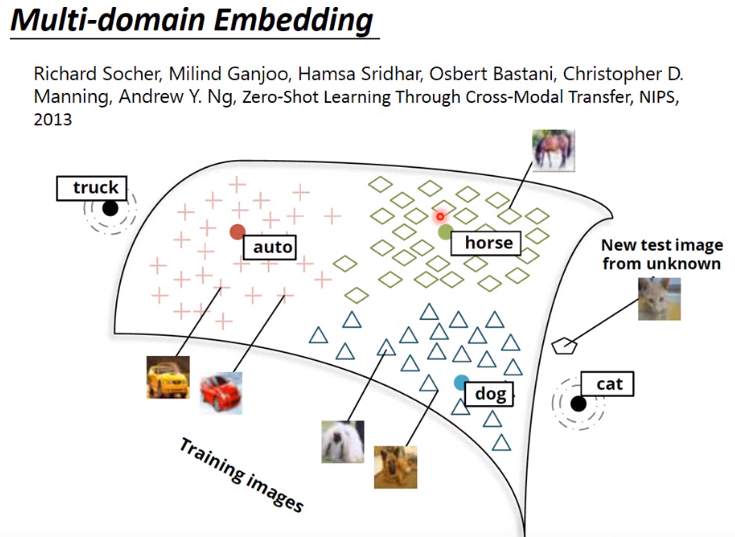
课中提到可以用来做多模态