8.7 RTDP
实时动态规划(RTDP)是动态规划值迭代算法的on-policy轨迹采样版本。RTDP的状态价值更新是根据DP中的值迭代方法来做的,公式如下。但不同于DP的一点是更新轨迹中出现的状态的价值。
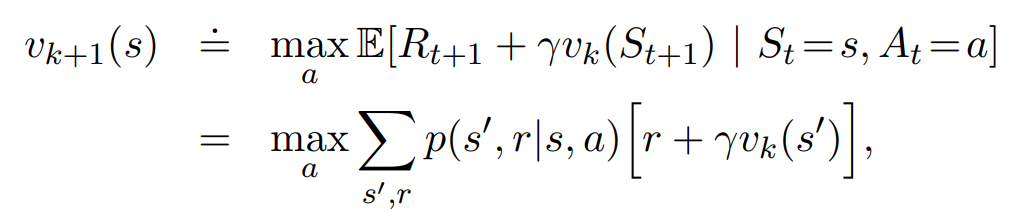
RTDP是一种异步DP。异步DP是指状态价值的更新顺序并非一个接一个的,而是不固定的。在RTDP中价值更新的顺序是根据其出现在轨迹(真实轨迹或仿真轨迹都可)中的顺序来的。
RTDP的特点:
- 利用值迭代的方法异步更新
- 根据采样的序列更新值函数
- 使用on-policy的策略,总是贪心的选择使得值函数最大的动作。
RTDP的优点:
- 得到最优的值函数就得到了最优的策略
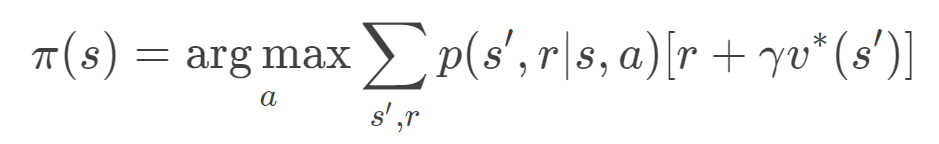
- RTDP可以更快的收敛
8.8 决策时规划
规划的方式可以有两种,一种是像之前的Dyna和动态规划类似的方法,利用模型产生的仿真经验计算价值函数。是对所有状态(或状态-动作对)的价值都进行计算,并且计算结果保存在表格中。这种方式关注全局的状态,叫做background planning。
另一种规划是对于特定的状态(或状态-动作对)而言的。对于当前状态$S_t$,会计算出agent当前要执行的动作$At$ 。但进行到下一个状态时,又重新开始规划。这种方式仅关注当前状态,称为决策时规划(decision-time planning)。
因为决策时规划是关注于当前状态的,所以从当前状态计算出来的价值和策略通常在选择完动作之后就被丢弃。这对于一些任务来说没有很大损失,并且这种方法非常适用于不需要快速响应的情况下。比如:国际象棋游戏程序中,每次移动可以允许几秒甚至几分钟的计算。
8.9 启发式搜索
决策时规划统称为启发式搜索。在启发式搜索里,对于每一个面临的状态,考虑一个可能的延续树。跟上一章中提到的数备份算法类似,区别在于不保存树中的值,当前状态做完决策之后,就可以将这棵树丢弃。
启发式搜索在一些对响应时间要求不太高的任务重非常高效,比如:围棋比赛等。因为搜索树密切关注那些当前状态之后可能出现的状态和行为,内存和计算资源仅为当前时刻的状态服务,可以大幅提高效率。
下图展示了利用启发式规则构建的一棵搜索树,我们可以自底向上各自执行单步备份。最终得到根节点状态的决策。
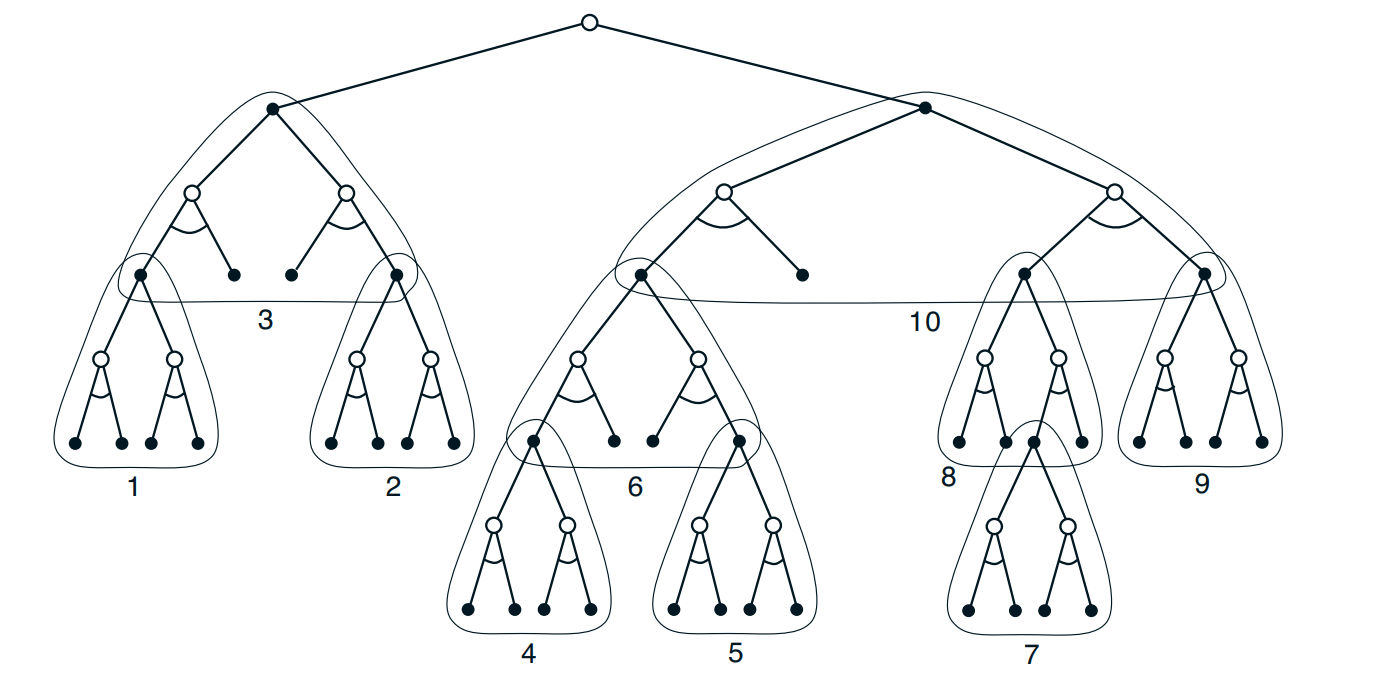
8.10 Rollout算法
Rollout算法是依据蒙特卡洛控制的决策时规划算法。具体的,对于当前状态,根据蒙特卡洛采样从当前状态开始的一些轨迹序列。要计算当前状态的价值,只需要将所有序列中得到的奖励求和取平均。如果想要得到动作价值,那就计算每个状态-动作对得到的平均奖励。
得到动作价值之后,就可以选择当前状态下,具有最高估计值的动作,执行这个动作,也就是和环境交互,转移到下一个状态,再对下一个状态进行同样的采样,以规划下一步的动作。
这种方法的本质是在提升当前的策略,而不是找到一个最优策略。因为它只对当前状态进行提升,其他状态的策略不变。在实际中这种算法十分有效。
rollout算法的效率受到以下几方面的影响:
当前状态下可能出现的动作数
仿真的轨迹长度
策略执行的时间
仿真轨迹的数量
当然,我们也可以通过并行仿真轨迹,以及使用截断的轨迹来提升算法效率。
8.11 蒙特卡洛树搜索
蒙特卡洛树(MCTS)是一个决策时规划算法,与rollout思想类似,对于当前的状态,它会采样一些轨迹序列,来帮助决策。区别在于MCTS在采样轨迹的过程中构建搜索树,并且搜索树可以引导采样的方向,使得采样出来的轨迹对于决策更有效果。
所以,MCTS非常适用于那些状态、动作空间较大的情况,例如:围棋游戏。因为它可以做到有效的剪枝。
具体的构建搜索树的过程包括四步:
- 选择:从根节点R开始,向下递归选择子节点,直至选择一个叶子节点L。具体来说,通常使用UCB值来选择最具“潜力”的后续节点。
- 扩展:如果L不是终止状态的节点,则随机创建其后的一个未被访问的节点,选择该节点作为后续子节点C。
- 模拟:从节点C出发,对轨迹进行模拟,直到到达终止状态。
- 反向传播:用模拟得到的结果来回溯更新整个过程的每个节点中获胜次数和访问次数。