看李宏毅老师的深度强化会感觉比较东西比较偏应用,正好要看多智体相关的东西,找了张伟楠老师的主页 http://wnzhang.net/ ,顺便复习下
bellman equation for value function
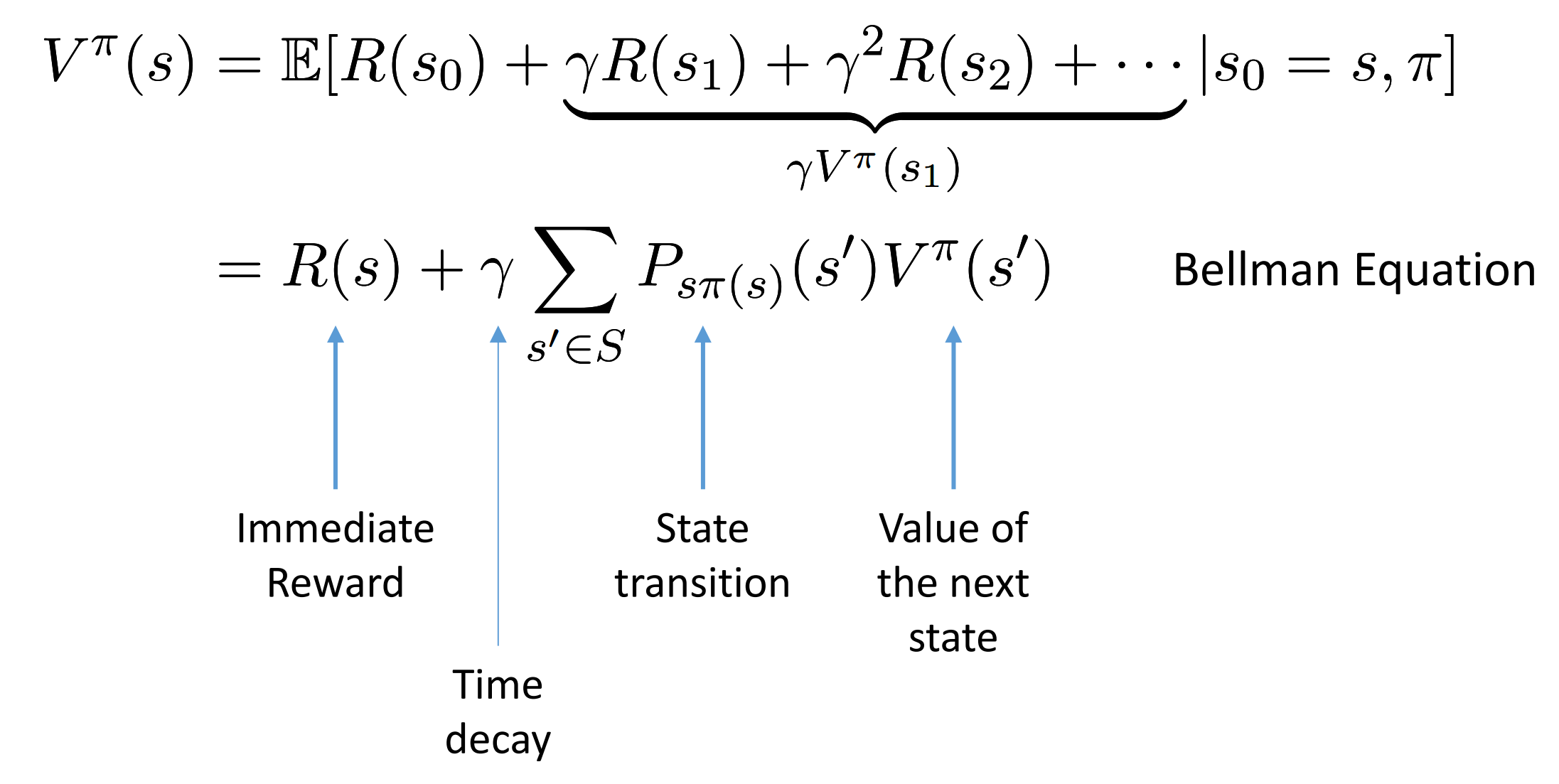
$P_{s\pi}$ is state transition. At state s, use policy pi
Optimal value function:
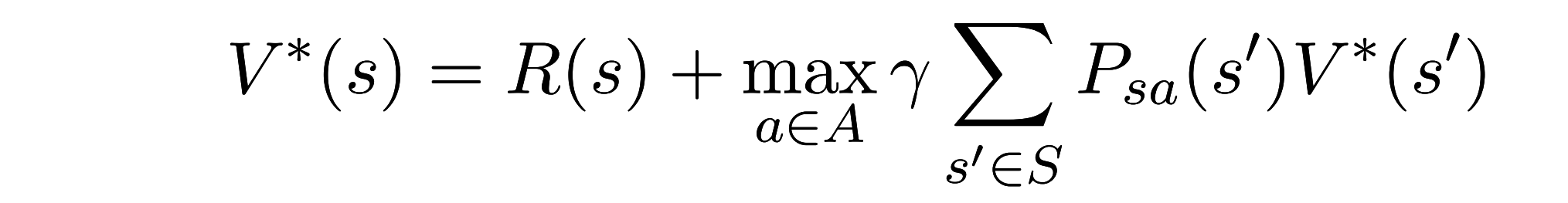
值函数迭代&策略迭代

需要已知转移矩阵和reward function
这里的reward在这里应该是假设只依赖于状态s
动态规划:
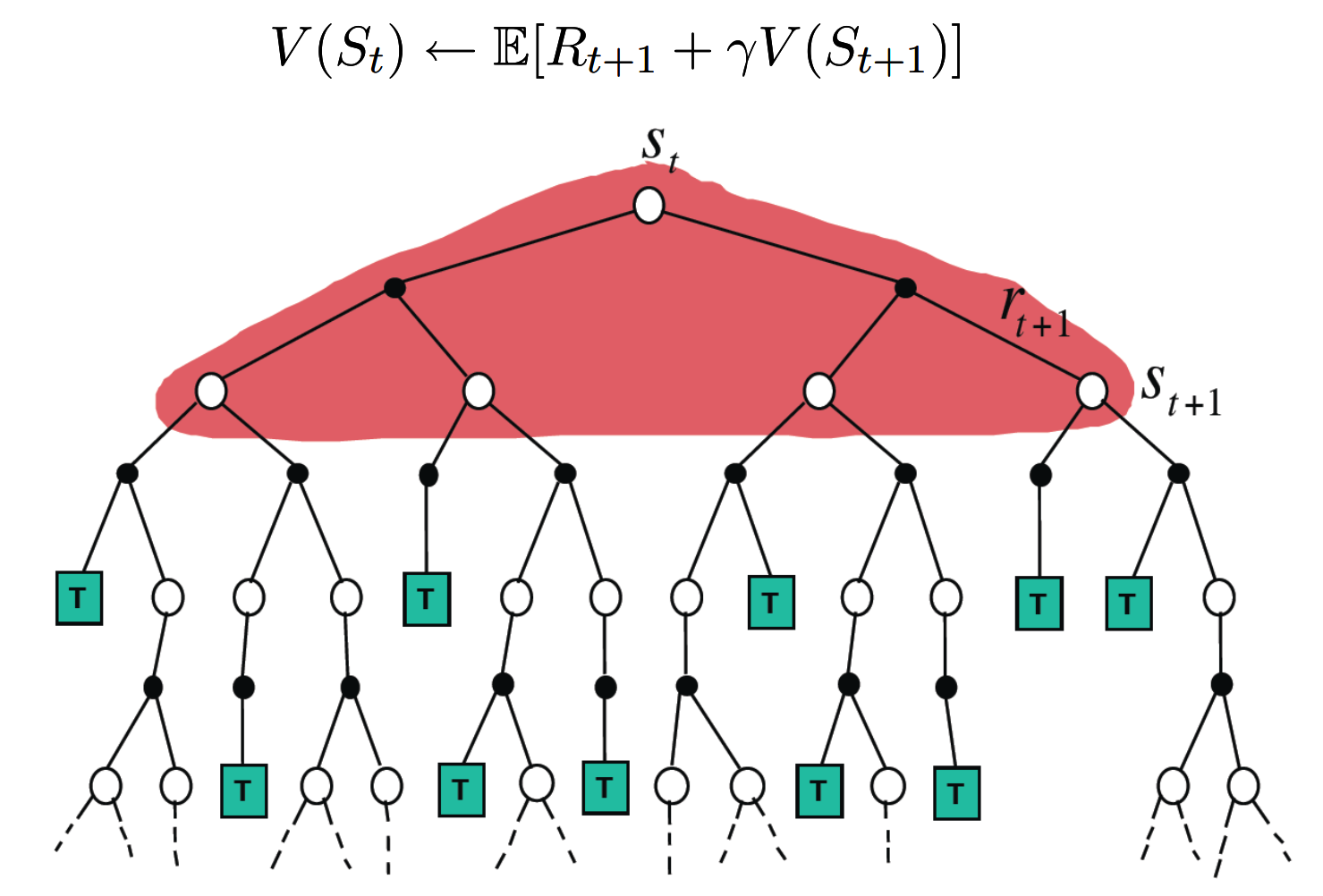
model free
model-free prediction
MC
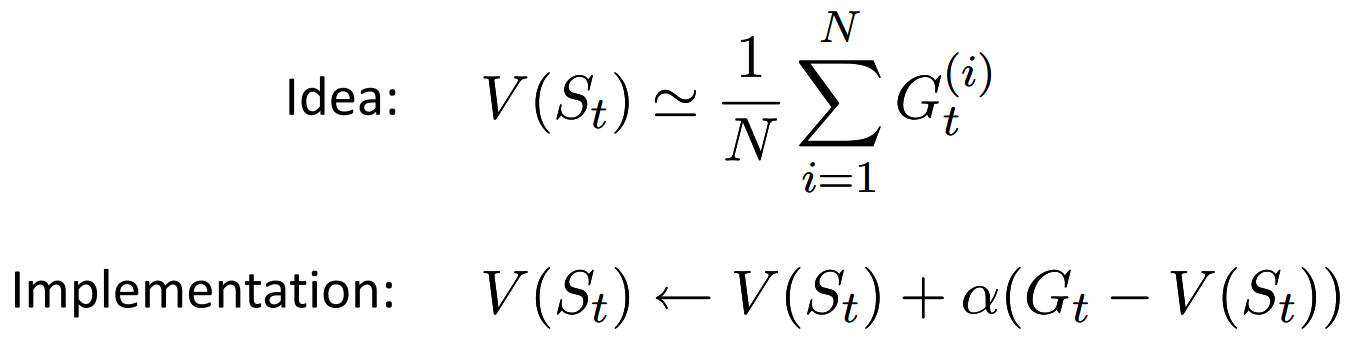
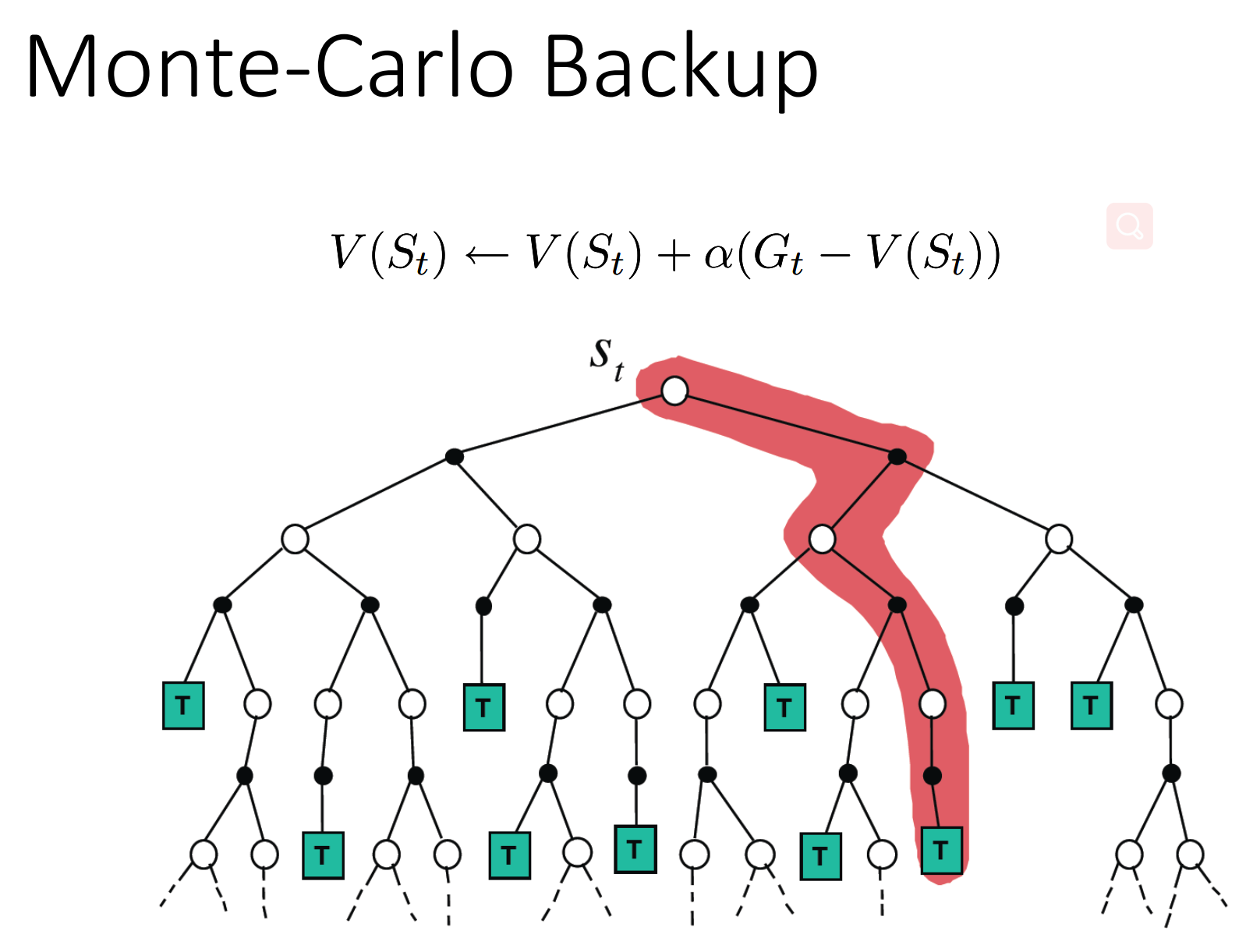
TD

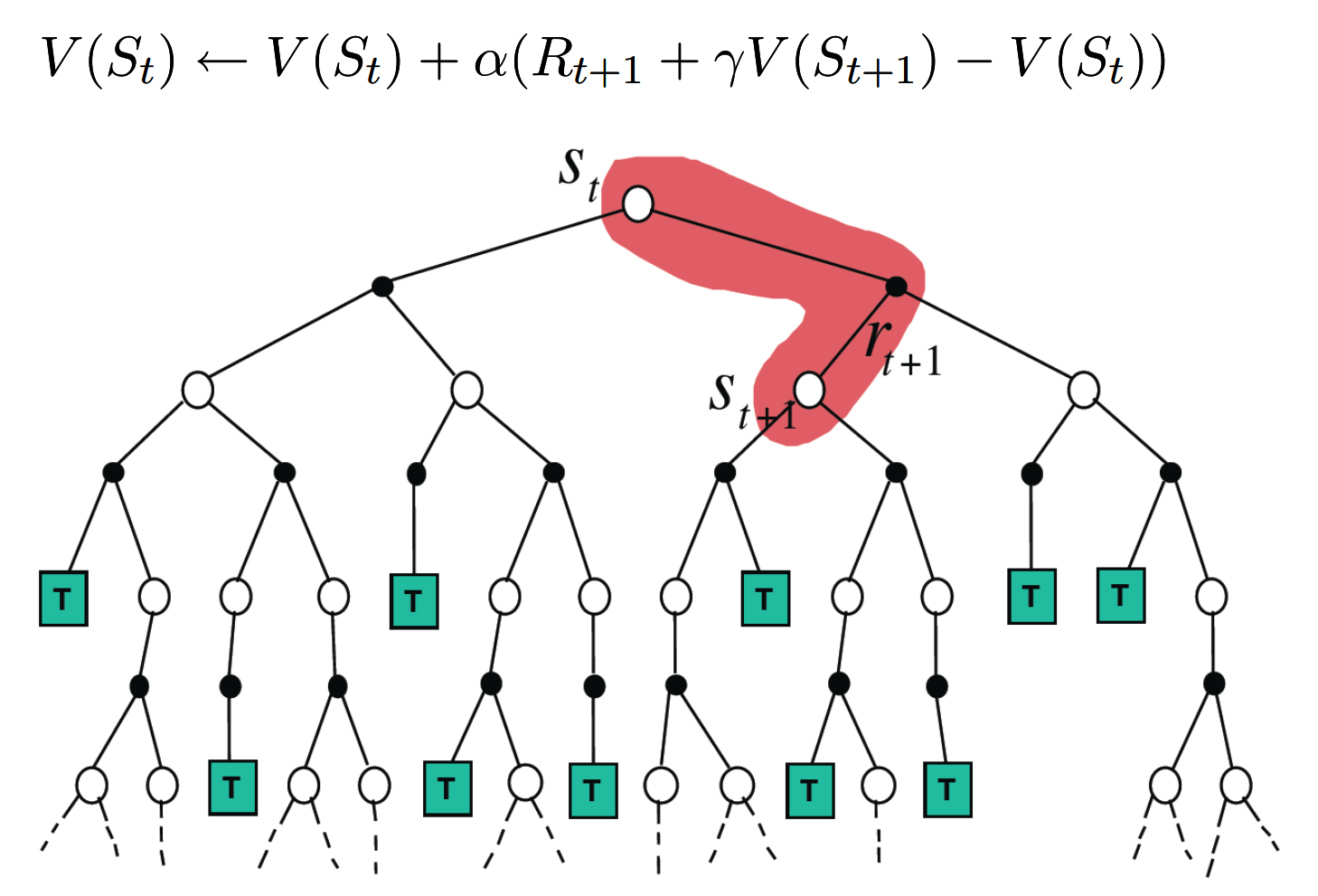
model-free control
$\epsilon$-greedy
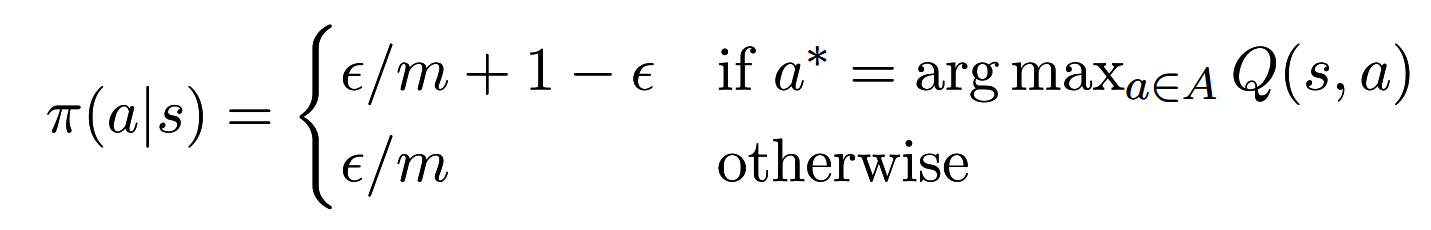
前面的mc和td的目的是估计出值函数,control是为了得到最优的policy
mc control
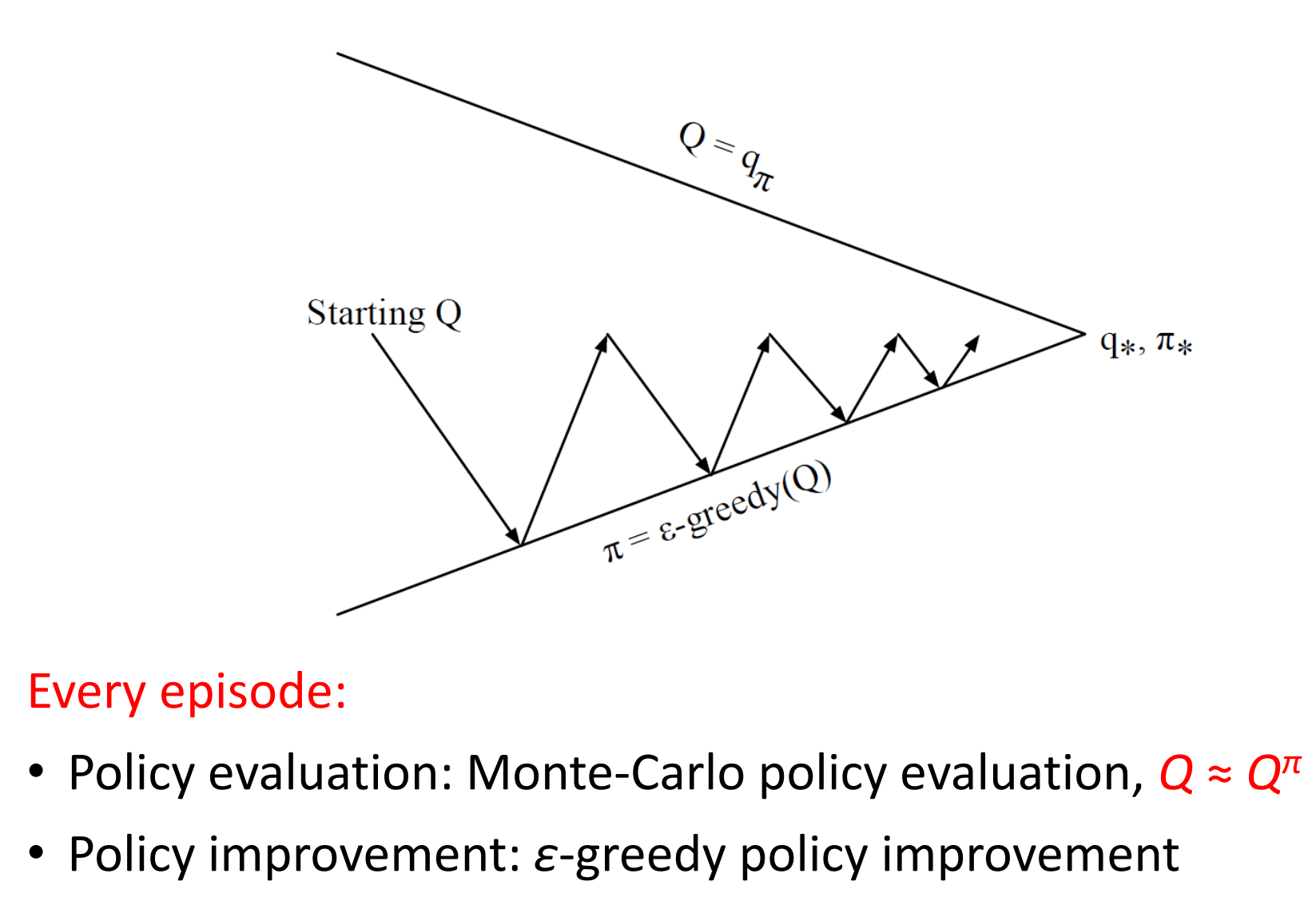
SARSA
state-action-reward-state-action
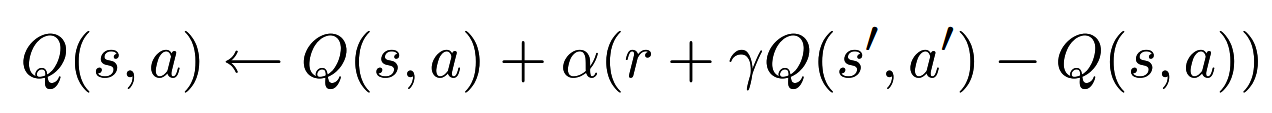
可以看到,这里是一个q的预测并不是control,但是q func得到之后就很容易得到pi,因为对于同一个s,选择最大的q(s,a)就可以了
在线学习版本:

似乎sarsa没有看到有用off-policy的,离线的可能就是q-learning了
Q-learning
可以参看之前的Q-learning(1)里面的q-learning,与本文的表示方式稍微有点不一样
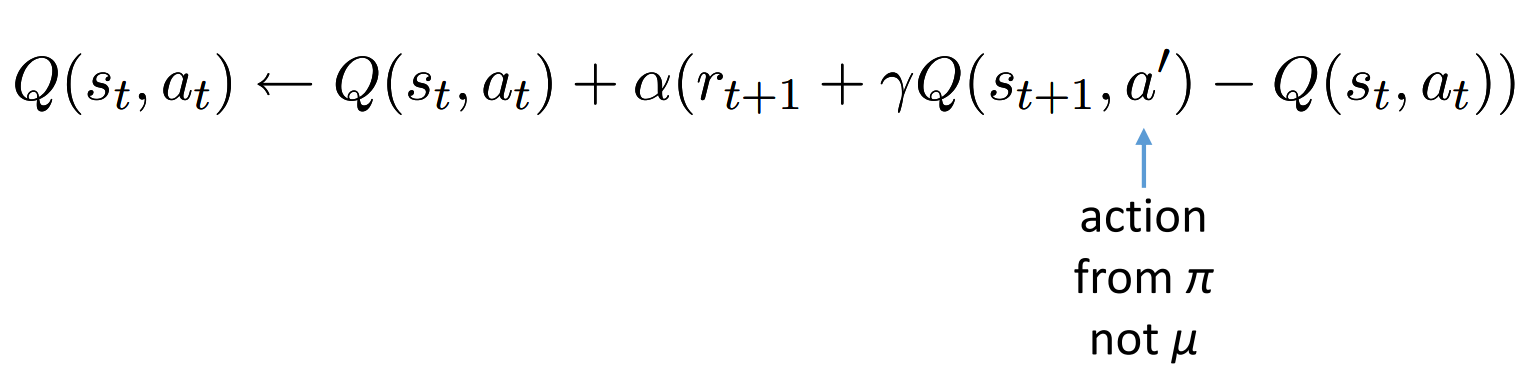
这里的$\mu$是 交互的策略