Q-learning
李宏毅老师主页18年机器学习教程: http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html (老师的2020年视频也出了)
值函数
值函数分为: State value function , State-action value function
状态值函数$V_\pi(s)$,是对状态s的估计
如何估计状态值函数
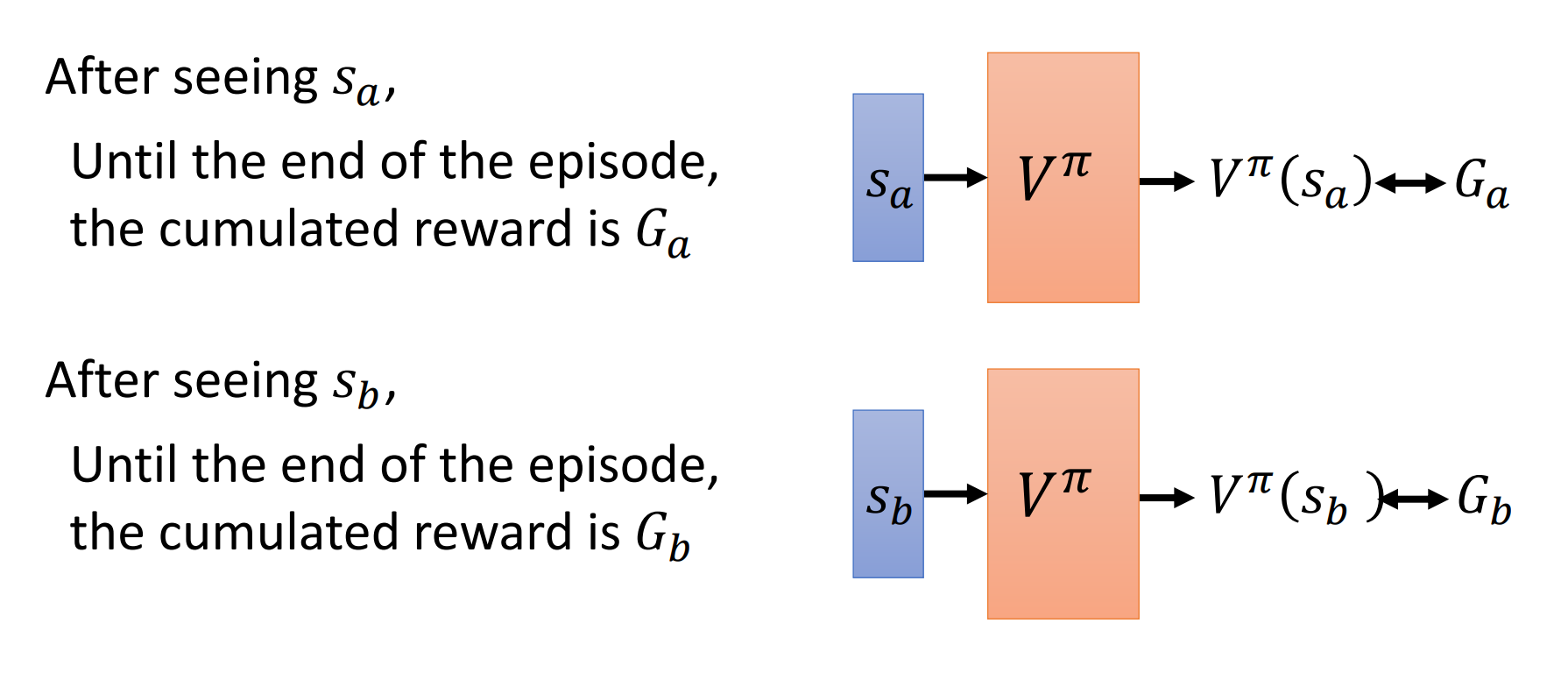
monte-carlo方法:
对多个episode求平均,可以用神经网咯拟合
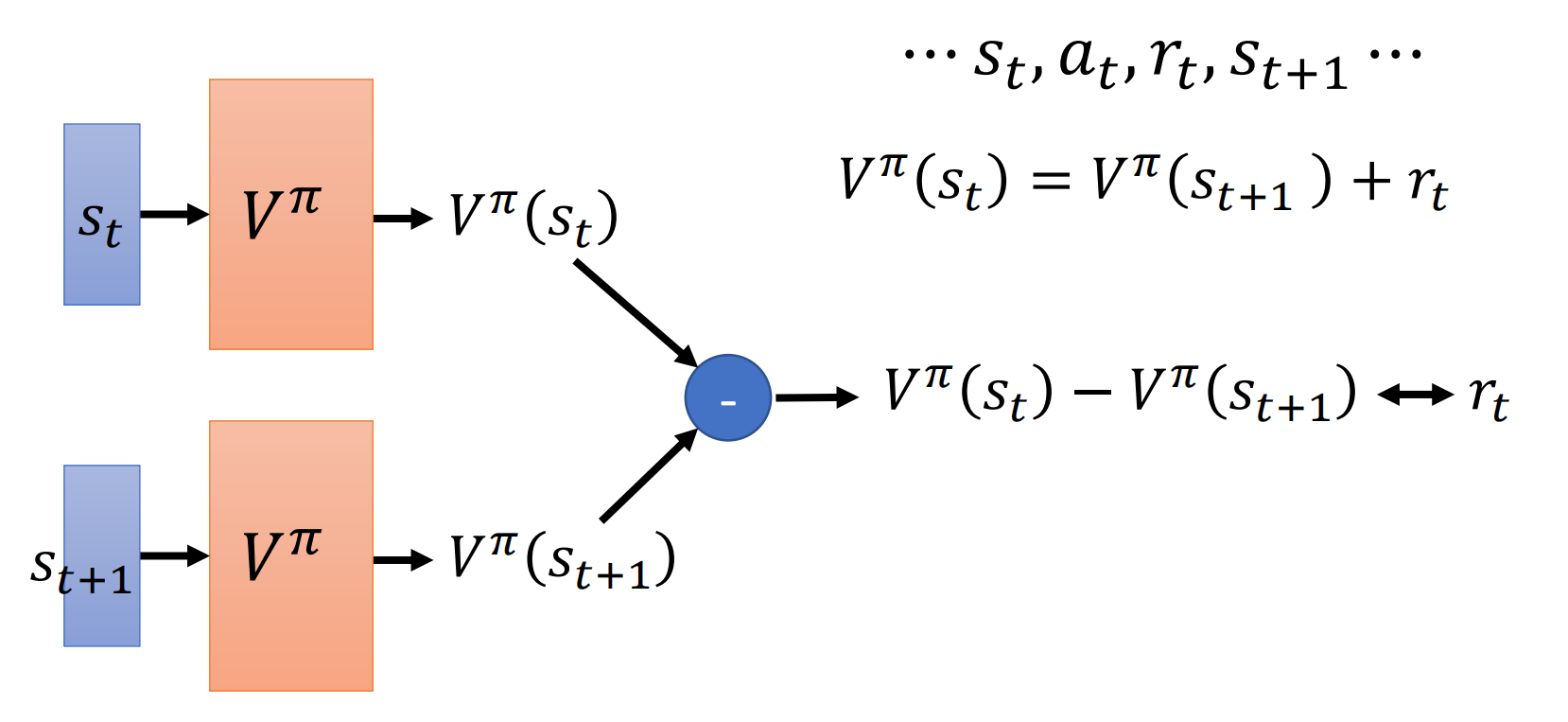
TD方法:
两个状态之间的值函数之差是reward,拟合reward就可以了
注:MC方法相较来说方差更大,并且这两种估计方法可能结果不一样大
Q-Learning
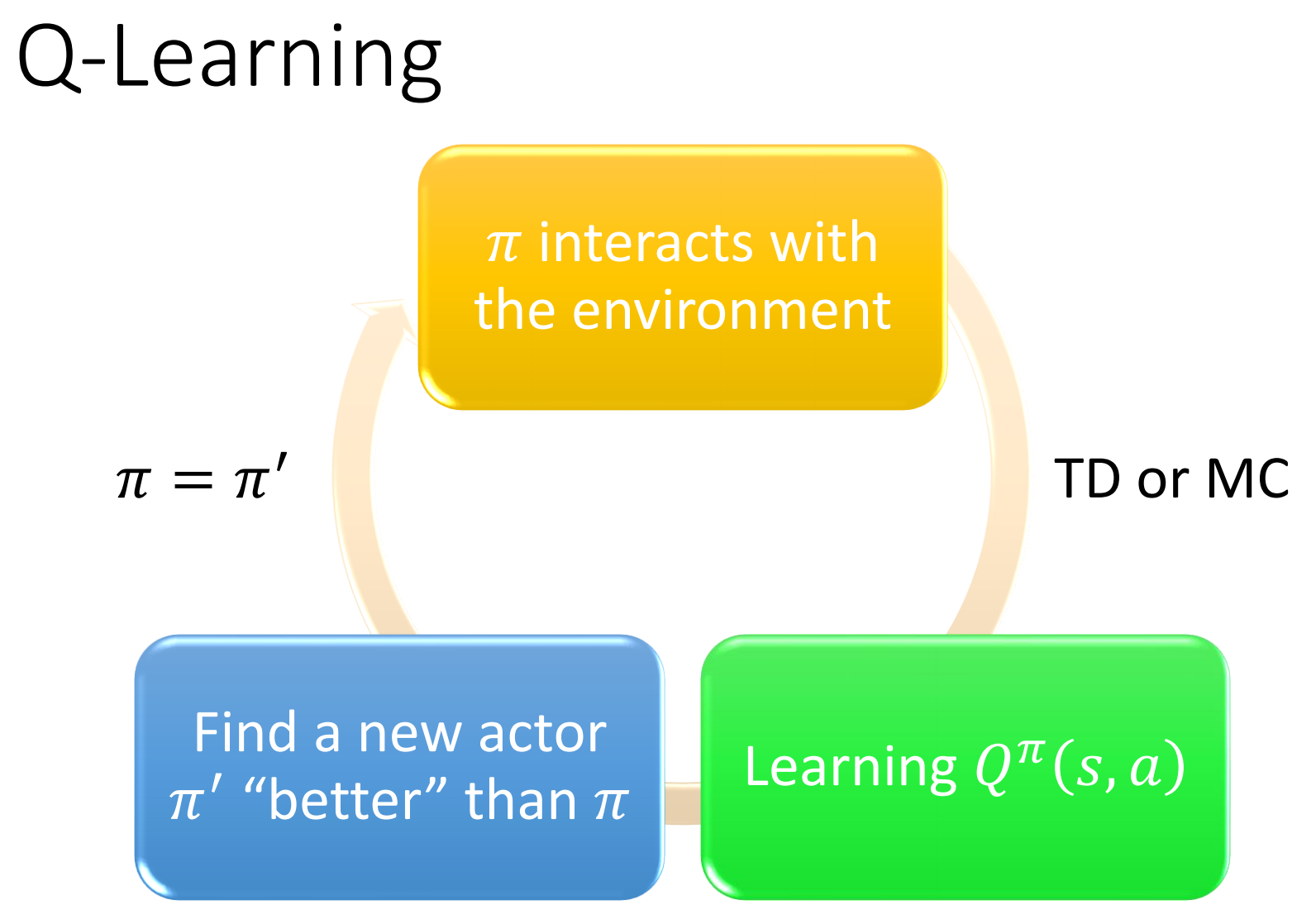
对于一个状态,选择一个最大的Q func就可以了
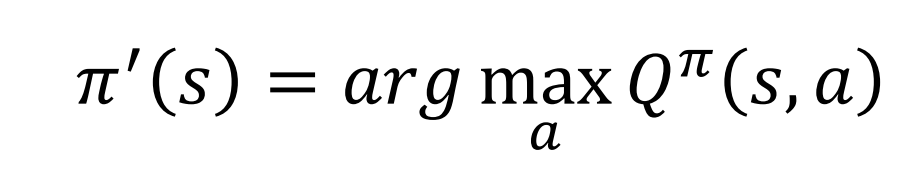
证明:
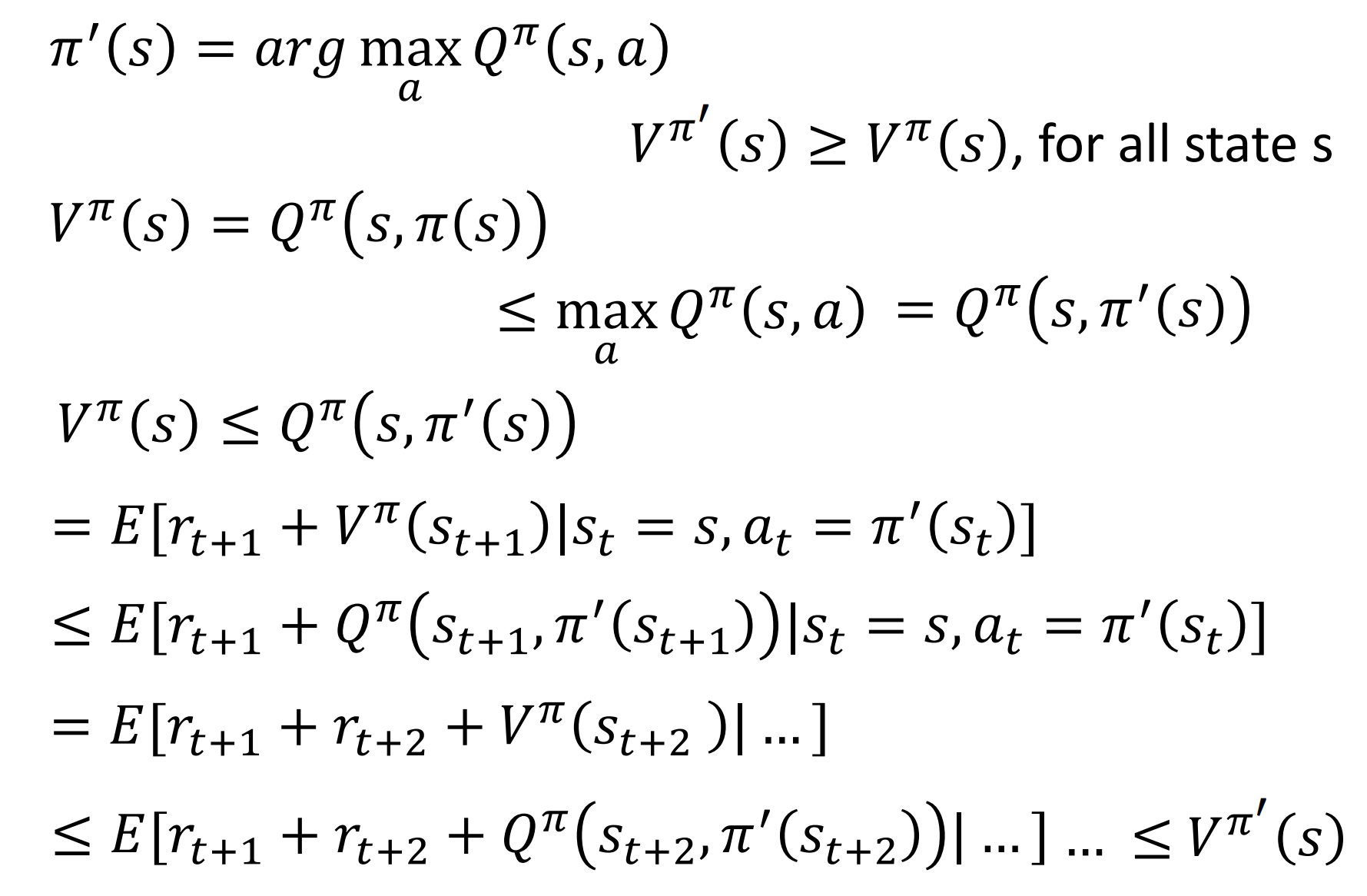
三个技巧
Target network
由于对q func的拟合是用的两个q之差与reward的比较,所以需要固定住一个
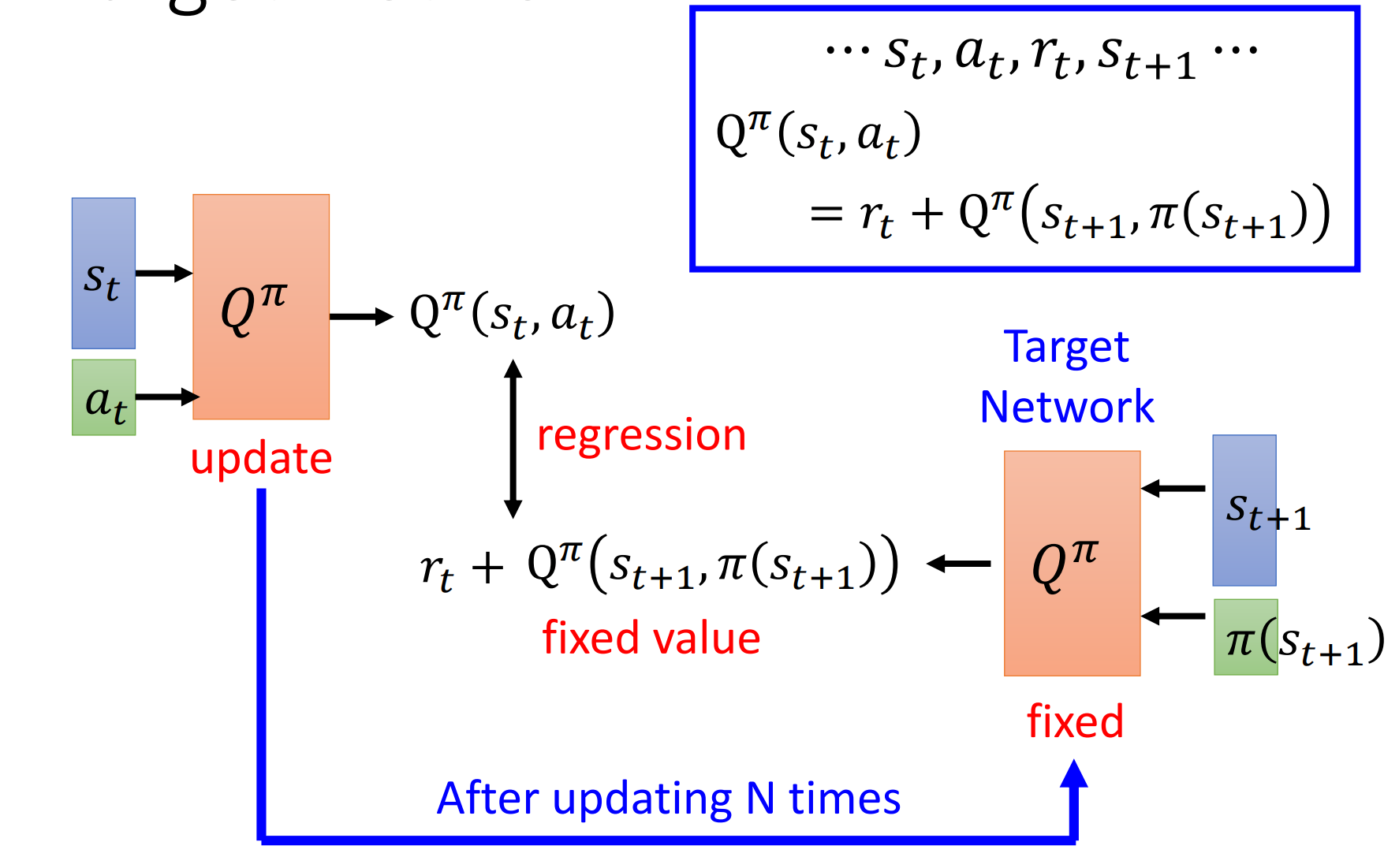
Exploration
策略更新的方式是选择q(s,a)最大的,这在前面阶段肯定是不合适的,因为很多(s,a)没有被遍历过。
两种解决方法如下图

replay buffer
弄一个缓存,里面放(st,at,rt,st+1)
每次从buffur里取一个batch,然后训练q func
Typical Q-Learning Algorithm
