paper:
https://arxiv.org/abs/1511.05952
Motivation
Experience transitions were uniformly, sampled from a replay memory. However, this approach simply replays transitions at the same frequency that they were originally experienced, regardless of their significance.
Main idea
Some transitions may not be immediately useful to the agent, They propose to more frequently replay transitions with high expected learning progress, as measured by the magnitude of their TD error. This prioritization can lead to a loss of diversity, which they alleviate with stochastic prioritization, and introduce bias, which they correct with importance sampling.
Methods
Goal is choosing which experience to replay.
example: ‘Blind Cliffwalk’
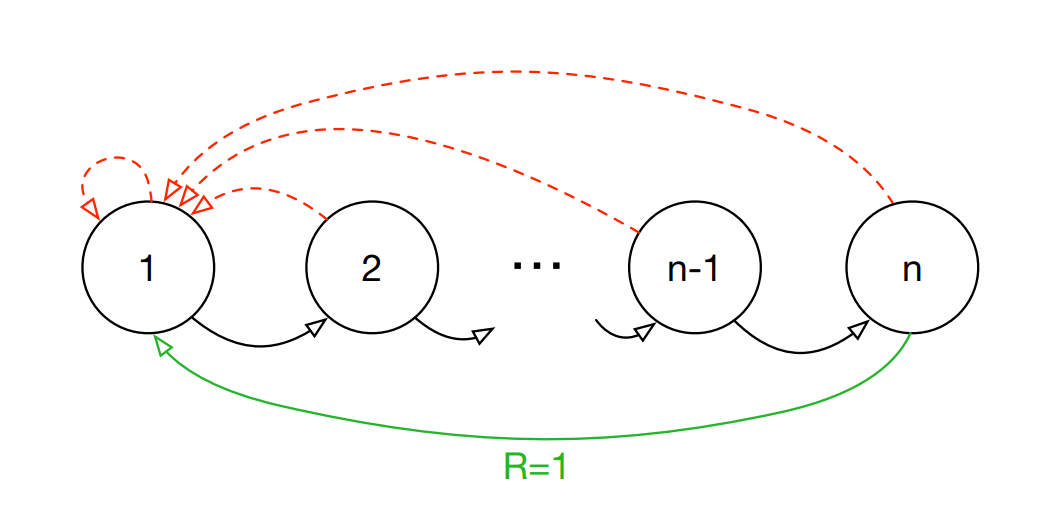
reward: The green arrow reward is 1, others 0
action: “wrong”: The dashed arrow, and the episode is terminated whenever the agent takes the ‘wrong’ action.
“right”: Taking the ‘right’ action progresses through a sequence of n states (black arrows), at the end of which lies a final reward of 1 (green arrow)
Feature: the successes are rare.
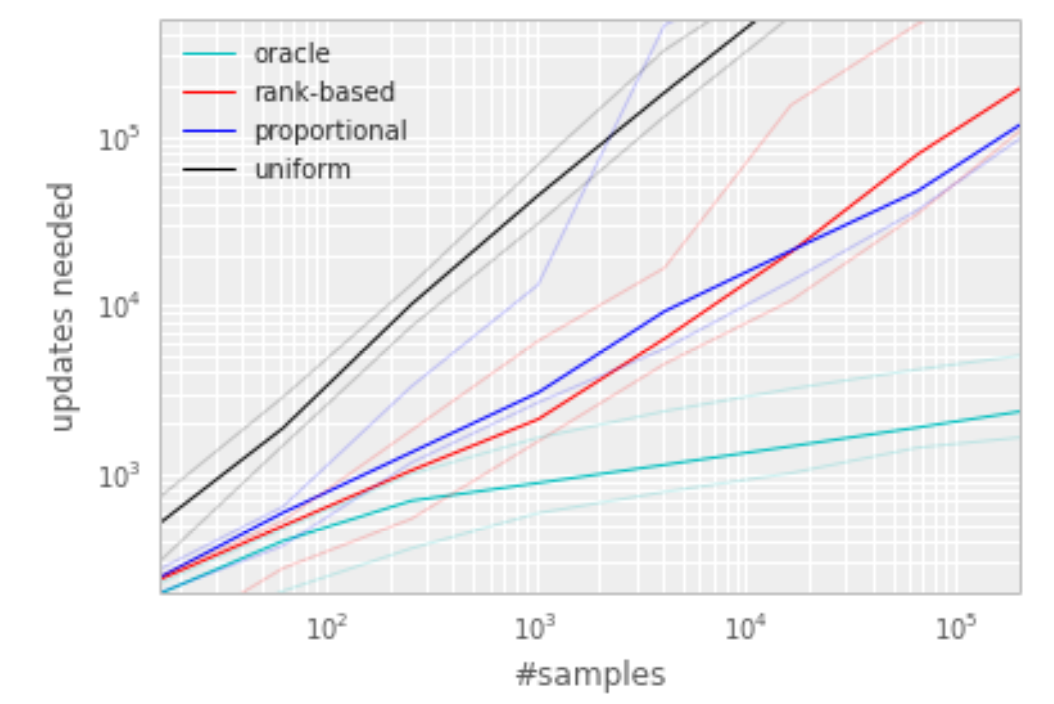
Uniform agent and oracle agent:
Uniform agent sample form buffer uniformly at random.
Oracle greedily selects the transition that maximally reduces the global loss in its current state (in hindsight, after the parameter update). (not realistic)
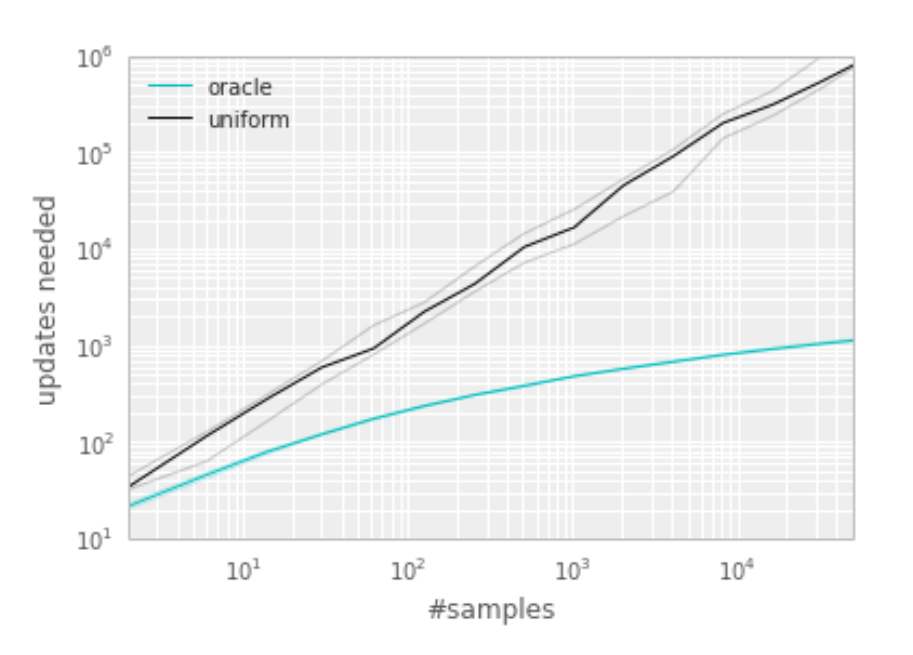
Median number of learning steps required to learn the value function as a function of the size of the total
number of transitions in the replay memory.
PRIORITIZING WITH TD-ERROR
The tuple stored is (st,at,rt,st+1,priority)
When we use Q-learning, we would get TD-error.
New transitions arrive without a known TD-error, so we put them at maximal priority in order to guarantee that all experience is seen at least once.
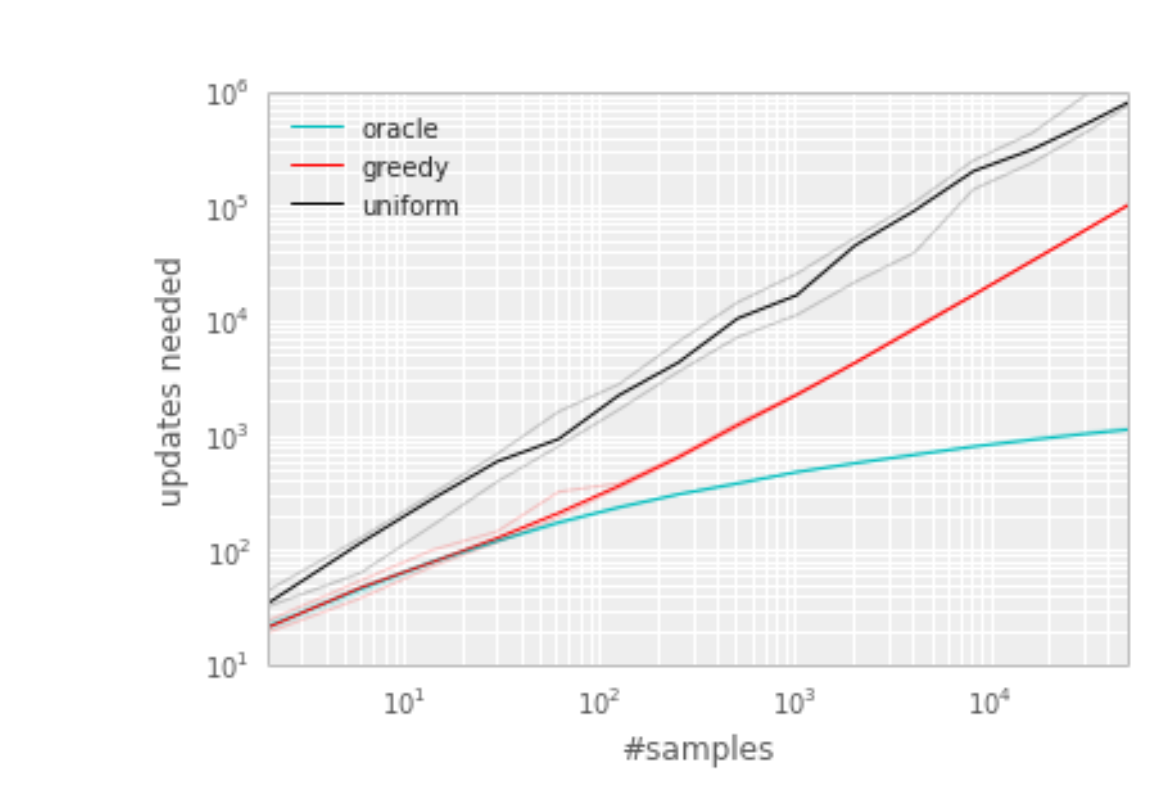
this algorithm results in a substantial reduction in the effort required to solve the Blind Cliffwalk task.
STOCHASTIC PRIORITIZATION
Greedy prioritization is lack of diversity that makes the system prone to over-fitting.
Stochastic prioritization’s probability:
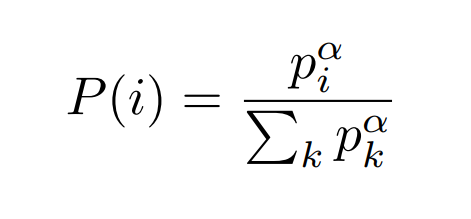
Two variants:
1) Rank-based variant
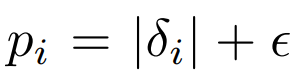
2) The proportional variant
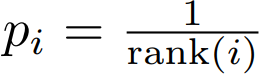
ANNEALING THE BIAS
Prioritized replay introduces bias, and bias can be corrected this bias by using importance-sampling (IS) weights
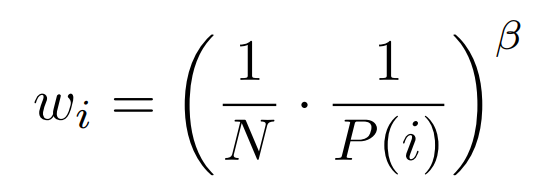
Update Q value using wiδi instead of δi.
In practice, we linearly anneal β from its initial value β0 to 1.
ALGORITHM

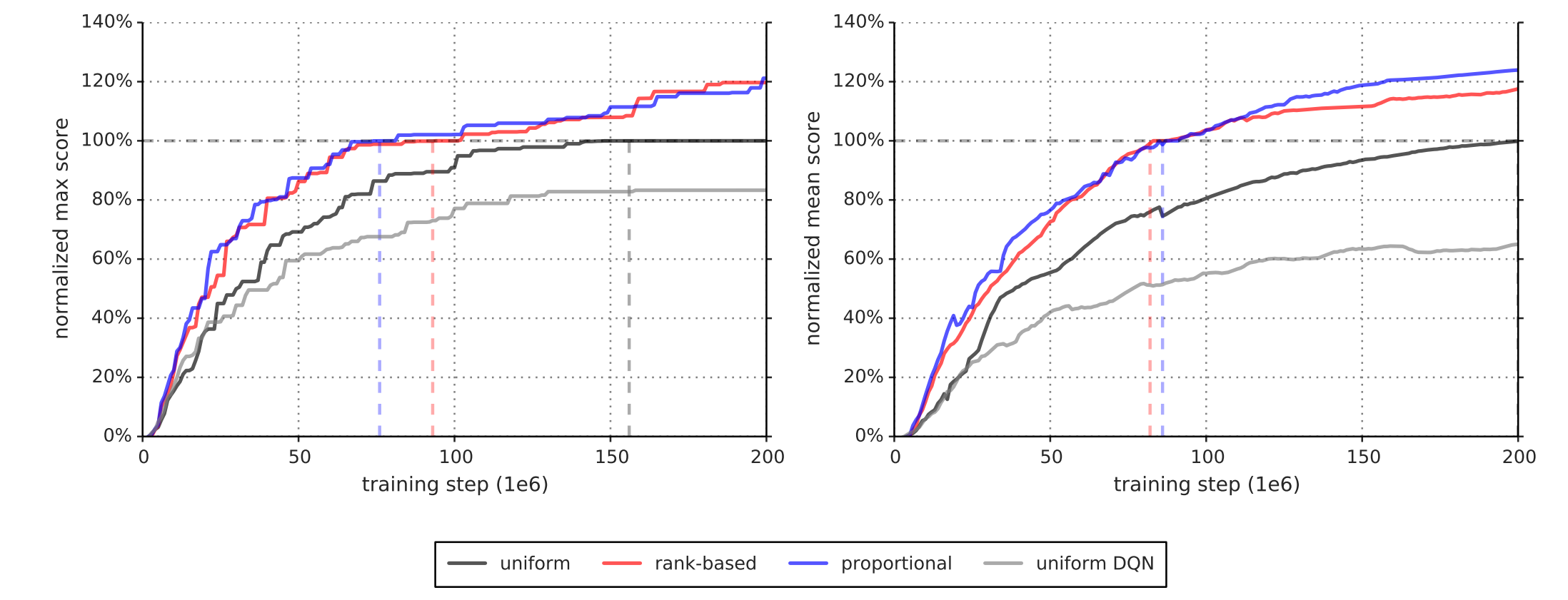
ATARI EXPERIMENTS
Average score per episode
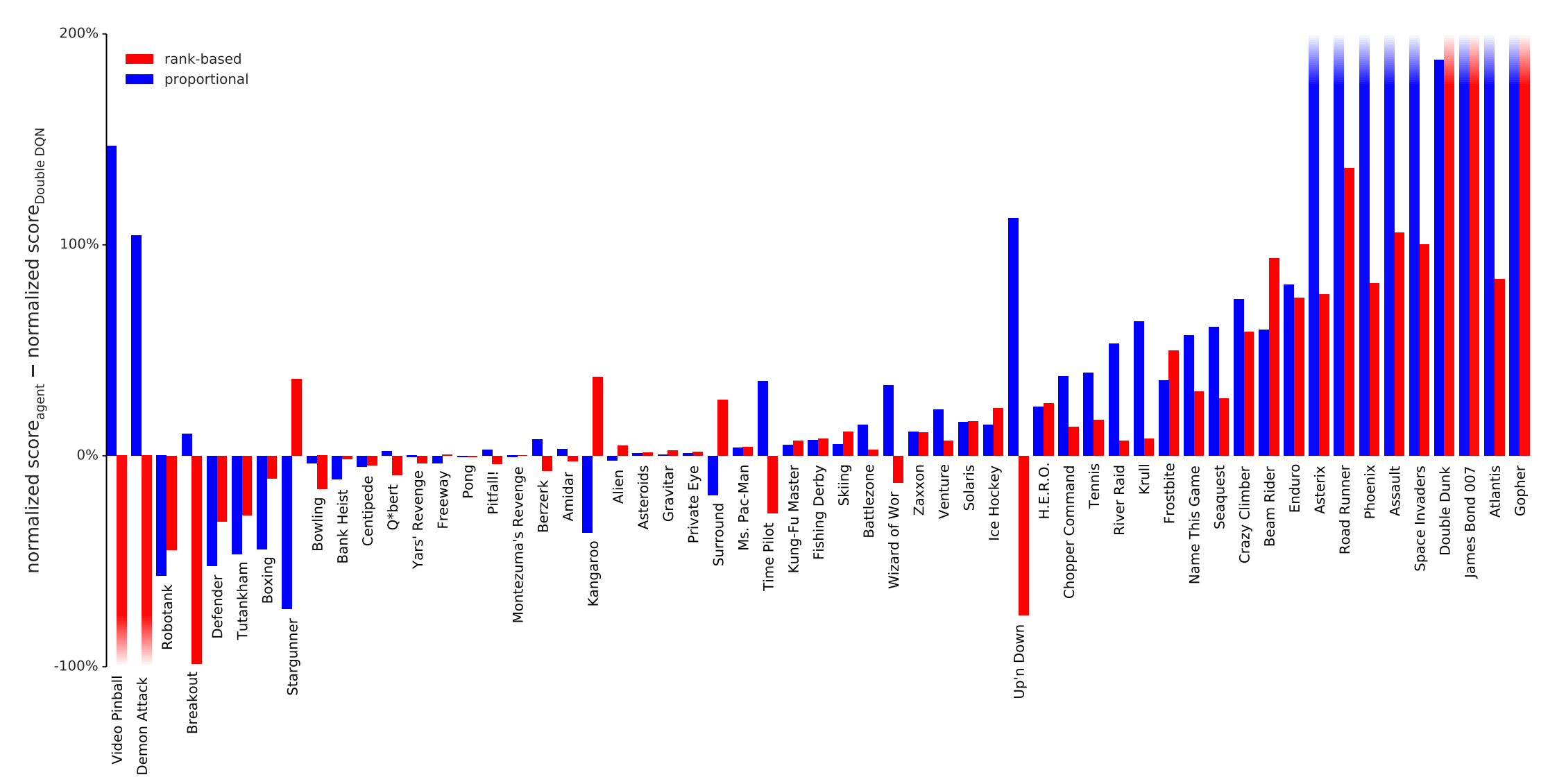
The learning speed