传送: https://www.aaai.org/Papers/AAAI/1998/AAAI98-106.pdf
多智体入门论文,之前看多智体的文章比较少且比较难看懂,找师兄推荐了篇比较早的简单的论文
自己总结的摘要:在单state的场景,通过重复训练来学习Q value,探索了智能体能观察到彼此(JALs)和智能体只知道自己(ILs)两种多智能体系统使用q-learning的表现,在满足一定条件的情况下都可以达到纳什均衡,但是不保证收敛到最优的纳什均衡,论文给出新的探索方式可以让JALs达到纳什均衡。
纳什均衡:对于每个智能体,在其他智能体不变策略的情况下,选择最优的策略
探索策略:
normal Boltzmann (NB) :
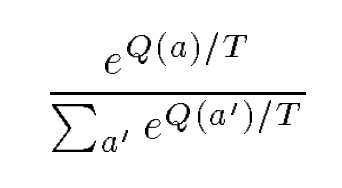
T随着训练降低
JALs的Q func
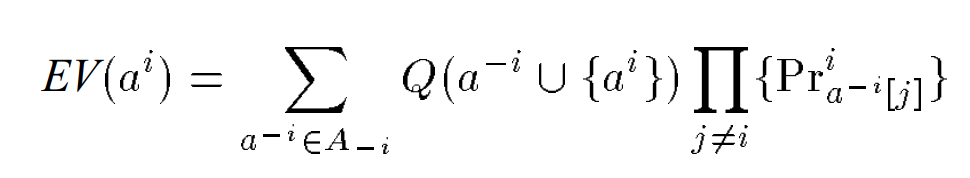
该方法不保证能到达最优

WOB和Combined方法更有可能到达最优(文章没有严格的证明)
总结思考:考虑公平在这篇文章上没有太大用处,因为本文的场景所有agent只有一个reward,只需要让reward更大,所以更多的考虑探索过程,如何有效的探索并且能让agent达成共识,在这个场景下可能直接使用一个agent,把action分成多维度可能更好。