介绍
github网址https://github.com/google/ml-fairness-gym
一个仿真环境
Fairness is not Static: Deeper Understanding of Long Term Fairness via Simulation Studies
- College admissions
- Lending
- Attention allocation
Fair treatment allocations in social networks
- Infectious disease
场景一: LENDING
(这个场景相关的设定有三种不同的,gym中文档中最重要,另外两篇论文里的辅助理解)
Delayed Impact of Fair Machine Learning这篇文章是one-step的,gym提供的是 many steps
个人被标记一个信用分数$\mathcal{X}:={1,2,…,C}$,分数越高表示越有可能带来正向收益,我的理解是越有可能还上款。
银行采用一个策略$\tau:\mathcal{X}\rightarrow[0,1]$表示选择的概率,我的理解是策略是对一个固定的分数,借钱的概率是相同的。

考虑两个群体,A、B,一个优势,一个劣势,分数分布为$\pi_A$,$\pi_B$
A群体占总体人数的$g_A$

没看懂这是个啥
例子中写了,如下

我的理解是这是赚多少钱

持续看不懂成功是指的成功借到钱?看后面的例子说是一个人在固定时间内还钱的概率
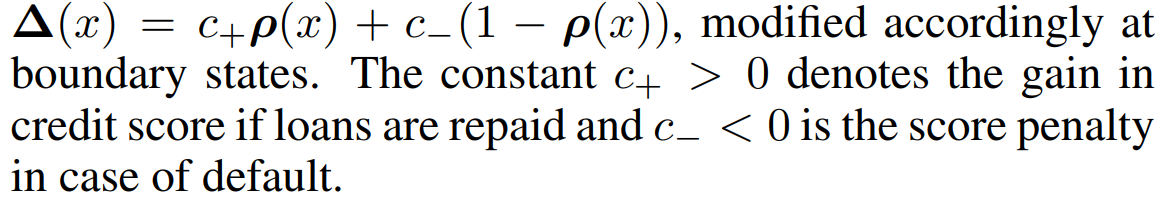
还钱后分数增加,不换分数减少
Fairness is not static中的说明
C表示分数
$\pi(C)$表示成功还款率
$p_{0}^{A}(C)$为A群体的C的分布
文档中的说明
https://github.com/google/ml-fairness-gym/blob/master/docs/quickstart.md

文档里这段之后给出了一些衡量的说明,但是看了也不知道怎么写自己的策略,现在能想到的解决办法是学习下python的debug,一步一步看下实例代码跑了哪些
1 | python experiments/lending_demo.py --num_steps=5000 |
The classifier is trying to find one or more appropriate threshold(s) for giving out loans. It will follow a simple rule. For the first 200 steps, it will give out loans to everyone. After that, it will use that data to find the threshold with the highest accuracy. (In this simulation, the cost of a false positive is exactly equal to the gain from a true positive, so accuracy is a reasonable metric to optimize).
(这里的最高的准确率怎么理解不清楚
手动分割,看了下lending_demo.py代码似乎还是比较易读
__future__包和absl之前没用过,可能稍微学一下, https://www.jianshu.com/p/2140b519028d 和
https://abseil.io/docs/ http://www.attrs.org/en/stable/
下面先记录下重要的代码
1 | # experiments/lending_demo.py |
先看看最简单的MAXIMIZE_REWARD是怎么写的
在agents/threshold_policies.py中看到MAXIMIZE_REWARD只是个枚举类
1 | class ThresholdPolicy(enum.Enum): |
lending中的Experiment对象所有的变量都是attr.ib(),暂时不影响理解
Experiment对象首先给了三种参数,env的参数,agent的参数,run的参数
然后定义了两个函数,scenario_builder和run
run里面调用scenario_builder
1 | env = lending.DelayedImpactEnv(env_params) |
这里调用的lending是environment中的

这里定义的lending的环境有这几种
1 | agent = oracle_lending_agent.OracleThresholdAgent( |
Threshold agent with oracle access to distributional data.
OracleThresholdAgent的父类是classifier_agents.ThresholdAgent,他的父类是ScoringAgent,他的父类是core.Agent
agent这里似乎是一些参数的定义,具体的agent的算法似乎是没有看到,reward的算法定义了,reward的func就几行暂时不看,下面看run
看了下重要的代码应该是这个
1 | metric_results = run_util.run_simulation(env, agent, metrics, self.num_steps, self.seed) |
然后找到
1 | action = agent.act(observation, done) |
用pycharm debug到这个agent的base class是ScoringAgent
agent.act调用的是ScoringAgent 中_act_impl
场景2 入学
看文章fairness is not static,入学这段开篇猛击,给钱改分?
in which individuals are able to pay a cost to manipulate their features in order to obtain a desired decision from the agent.
个人知道agent的rule,可以 e.g., by investing in test prepcourses
暂时理解,agent的rule是知道的,申请者可以花费去改分,agent可以预测更改,然后实施一个robust的决策
if the agent has knowledge of the cost functions so that it can determine how much applicants must pay to manipulate their scores, then the agent can learn a best-response decision rule that nearly recovers the accuracy of the optimal decision rule on unmanipulated scores.
这段谷歌翻译翻译的recover是恢复,这样就可以理解了
robust的决策可能比较保守,使得qualified的人改分数,不qualified的人too costly(这样好像是好的)
但是可能对于disadvantage的群体,合格者可能会花不成比例的钱
trade-off的是一边要升高分类的准确,一边要减少qualified的申请人(文中这里没指定是弱势群体比较奇怪)
研究目标:
- 单步和长期训练的区别
- unmanipulated score and their true label之间的noise对于长期训练的影响
结论:
if manipulation is occurring, practitioners should consider the fairness implications of robust classifcation
even if they are not deploying a robust agent.